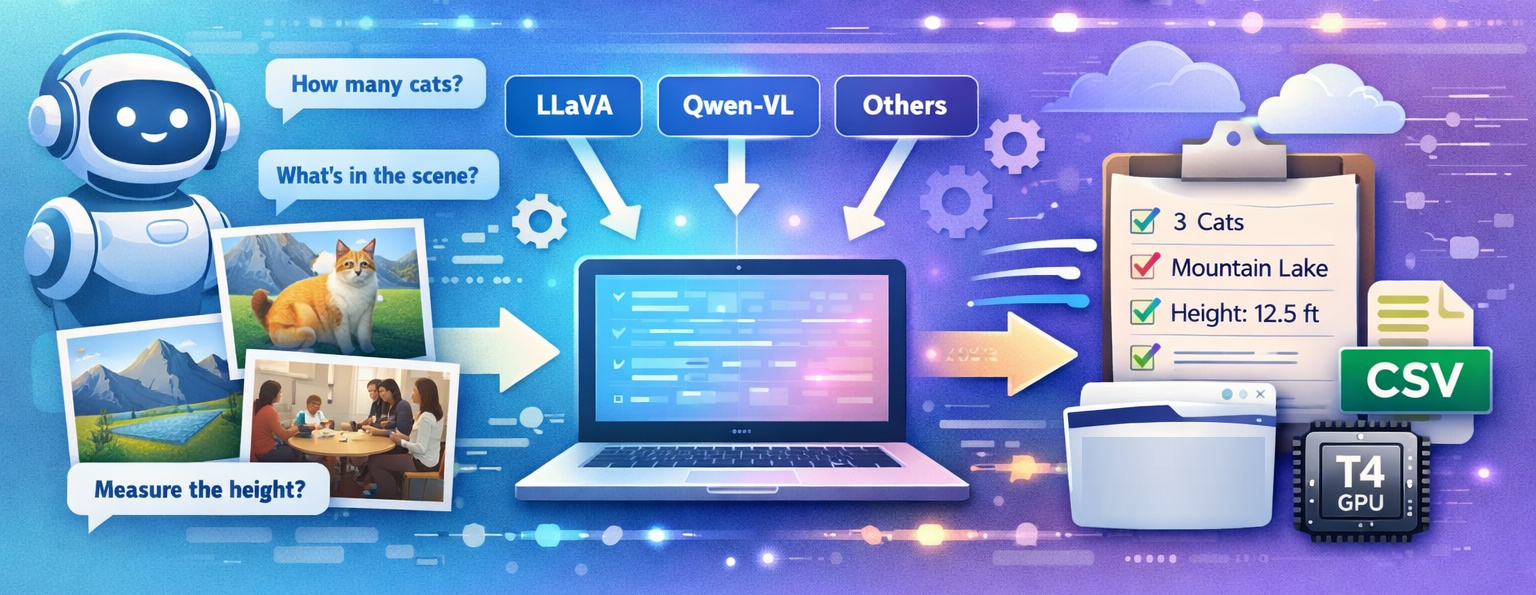
Introducing UVLM: A Free Tool to Compare AI Models That Understand Images
UVLM is a free, open-source tool for loading, testing, and comparing Vision-Language Models on custom image analysis tasks. Running entirely in Google Colab, it lets researchers and practitioners benchmark multiple AI models using the same prompts and images — no coding, no GPU ownership, no model-specific pipelines. This post explains what VLMs are, why comparing them matters, and how to get started in five minutes.